Selection
First, the homework from Lab W.
What is Model Selection?
What is model selection? To answer this question let's contrast model selection with parameter estimation. In the Optimization Lab, we fit lines to data. We were doing parameter estimation, trying to estimate the parameters m and b, in the formula for a line y = m*x + b. Recall my examples: we fit a line to nearly linear data and another line to nearly parabolic data.


Clearly, in the second case, it would be more appropriate to fit a parabola to the data, rather than a line. How would we do that?
A parabola is described by the formula: 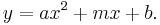 This is a line with a new term,
This is a line with a new term, 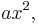 added. To fit a parabola the procedure is almost the same. First determine the errors in the data:
added. To fit a parabola the procedure is almost the same. First determine the errors in the data:
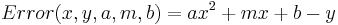
Now define the penalties, (let's be sensible and use LS rather the UG penalties):
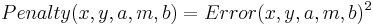
And finally the cost function
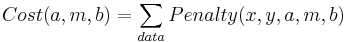
Now we tweak the three parameters (a,m,b) using, for example the Nelder-Meade method we studied last week. Of course MATLAB has its own routines for solving this problem based on Linear Algebra that are much better than Nelder-Meade.